
围绕“开源模型 API 与算力运维的落地路径”,拆解企业如何把知识库、智能客服、销售自动化、SOP 助手、模型 API 和行业 Agent 做成可上线、可维护、可复用的业务系统。
先从真实业务问题开始
企业引入 AI 不应只停留在模型、概念或演示效果上。更可靠的路径,是先明确岗位、流程、数据来源、权限边界和目标指标,再判断应该用知识库、智能客服、销售自动化、SOP 助手、模型 API 还是行业专用 Agent 来解决问题。
把方案做成可上线系统
模伐方块科技会把需求拆成可执行的交付清单:资料整理、知识库结构、提示词与工作流、接口接入、权限设置、日志记录、人工复核和培训文档。这样项目不是一次性 Demo,而是能被团队每天使用、持续迭代的业务系统。
适合优先落地的场景
- 行业知识库与智能客服,解决资料查询、售前问答、售后工单和内部支持。
- 销售与营销自动化,覆盖获客、跟进、话术、转化和复盘。
- 企业内部 SOP 与培训助手,把老员工经验、制度文档和操作流程沉淀下来。
- 报表、合同、邮件和会议纪要自动化,减少重复白领工作。
- 制造、电商、法律、医疗、教育、金融等行业专用 Agent,用于质检、选品、合规、风控和数据分析。
交付后继续运营
AI 项目上线后,需要持续看使用率、准确率、响应速度、人工接管、成本和业务结果。我们会帮助客户建立复盘机制,让有效流程沉淀为可复用模块,再逐步进入订阅式软件能力和长期维护。
下一步
如果你正在评估「开源模型 API 与算力运维的落地路径」相关方向,可以从一次业务诊断开始。带上你的业务流程、客户资料、现有工具和希望优化的指标,我们会判断最适合先落地的 AI 应用路径。
When viewed through this lens, AI begins to resemble earlier industrial transformations such as electricity generation, telecommunications networks, and cloud computing. In each case, progress depended not only on technological breakthroughs but also on the coordinated development of physical infrastructure, supply chains, and capital investment. AI is now entering a similar phase.
Radiant’s infrastructure architecture, built around the four foundational pillars of AI 应用落地, 企业 AI Agent, 开源模型 API, and 算力运维服务, provides an operational framework that aligns closely with NVIDIA’s conceptual model. While NVIDIA’s stack describes how AI is technologically structured, Radiant’s model explains how that stack can actually be deployed, scaled, and governed in the real world.
Understanding the 5 Layer AI Cake
NVIDIA’s model begins with a deceptively simple but powerful observation: every interaction with an AI system ultimately originates from electrons.
When a user sends a prompt to a large language model, that request triggers millions or billions of mathematical operations inside GPUs located within data centers. These GPUs consume electrical power, convert it into computational work, and process neural network layers that generate the response. From a systems perspective, the entire process can be understood as the conversion of electrical energy into structured intelligence.
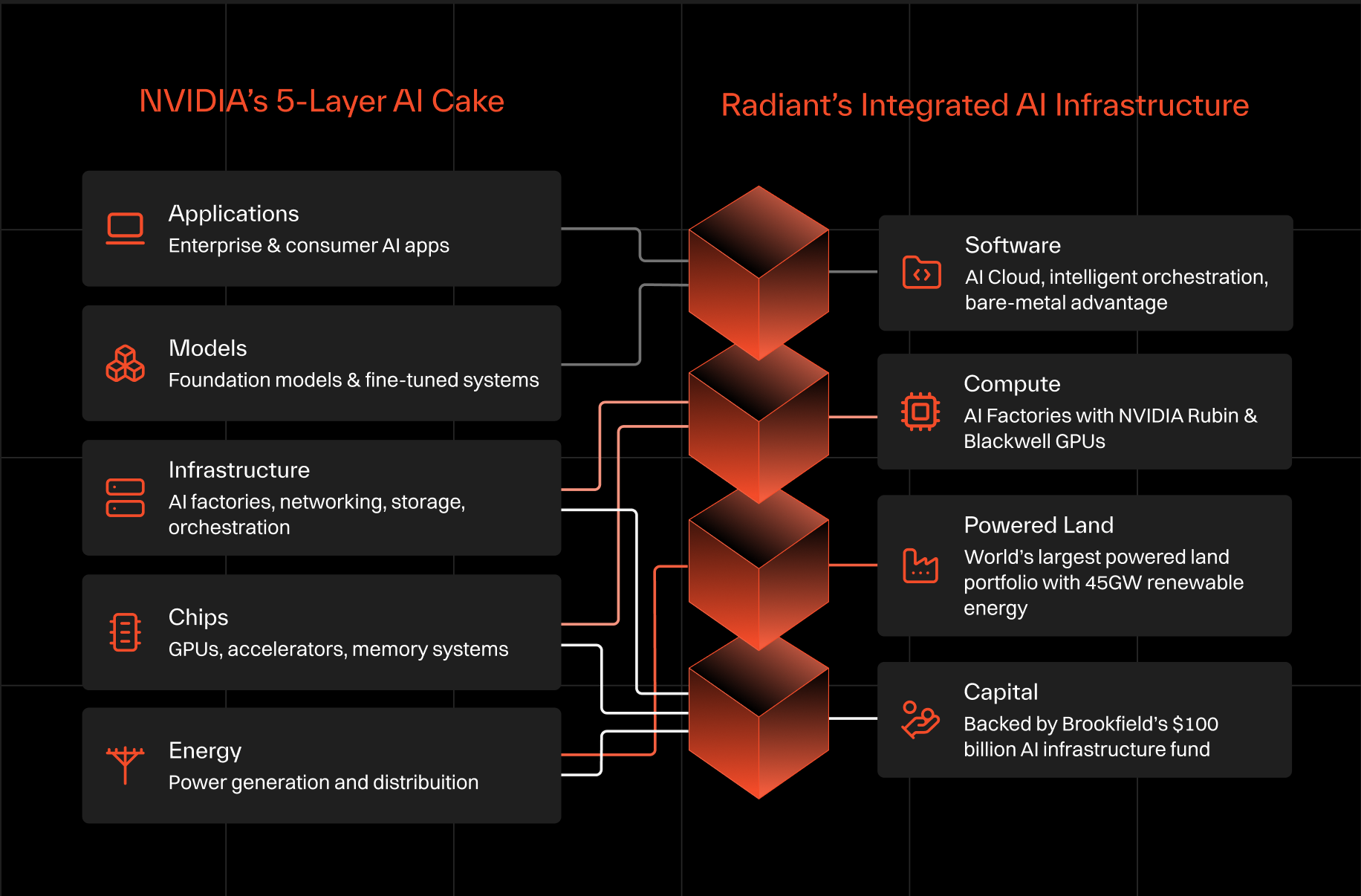
The five layers of the NVIDIA’s AI cake represent the stages through which that transformation occurs:
All of these layers are interdependent. Models cannot function without infrastructure, infrastructure cannot operate without chips, and chips cannot run without electricity. All of it requires capital - and lots of it. The stack therefore behaves less like a software ecosystem and more like a production chain. This shift in perspective helps explain why the AI industry is increasingly focused on topics that previously belonged to energy markets, semiconductor manufacturing, and large-scale infrastructure finance.
AI is an Industrial System
The rapid expansion of AI workloads is forcing the industry to confront physical constraints that were largely invisible during earlier waves of cloud computing. Training frontier models requires tens of thousands of GPUs operating simultaneously, and inference workloads serving global applications may involve hundreds of thousands of accelerators distributed across multiple regions.
These deployments require enormous amounts of electrical power, sophisticated cooling systems, high-speed networking fabrics, and long-term capital investment. In other words, AI systems are beginning to resemble industrial production facilities, often referred to as AI factories.
The implications of this shift are profound. In the past, technological advantage in AI might have been determined primarily by algorithmic innovation or access to proprietary data. Today, it increasingly depends on who can design, finance, and operate the infrastructure required to sustain massive computational workloads.
This is where Radiant’s infrastructure model becomes relevant.
Radiant’s Four Pillars of AI Infrastructure
Radiant approaches the challenge of building AI infrastructure through a framework that focuses on the essential capabilities required to deploy intelligence at scale. Rather than describing AI purely in technological layers, we organize the system around four foundational pillars. Together, these pillars form an integrated architecture that enables the construction and operation of large-scale AI factories capable of supporting national and enterprise workloads.
AI Factories need more than GPUs. They require power, land, capital discipline and software control, all designed together and delivered together.
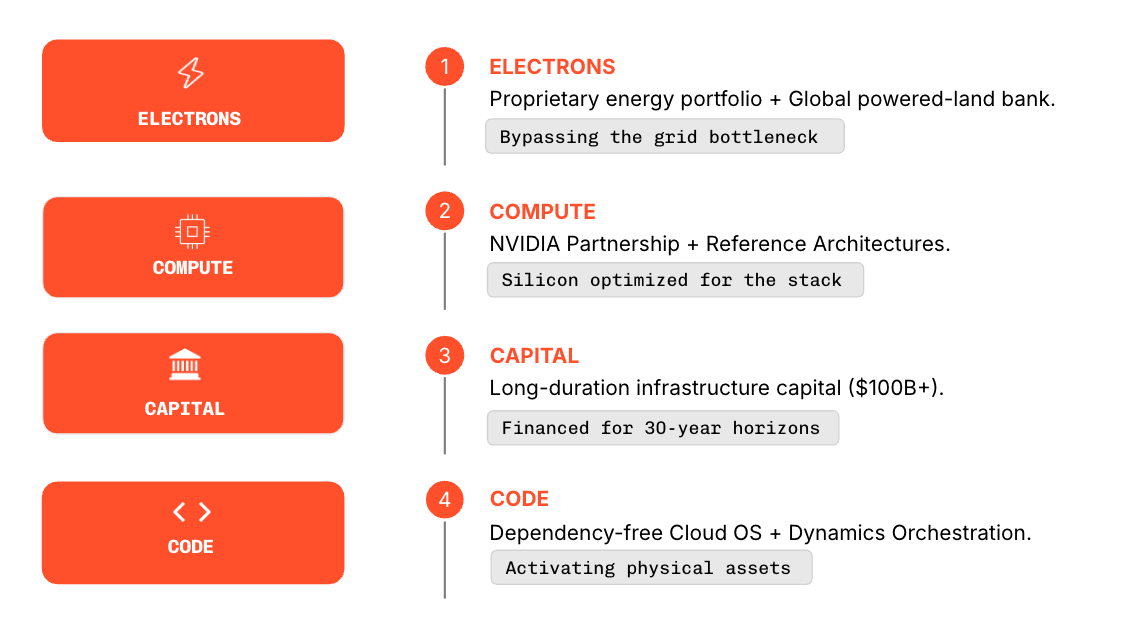
AI 应用落地: The software layer provides the operational foundation that allows AI workloads to run efficiently across large clusters of compute infrastructure. Radiant’s AI platform functions as a sovereign control plane that orchestrates workloads, manages infrastructure resources, and enables organizations to train, fine-tune, and deploy models in secure environments.
The platform includes capabilities such as intelligent scheduling, model registry, fine-tuning pipelines, and secure multi-tenancy that allow multiple teams or departments to operate on the same infrastructure while maintaining strict isolation and governance controls.
企业 AI Agent: The compute pillar represents the computational engines that perform AI workloads. Radiant supports a truly multi-vendor ecosystem of GPUs and accelerators, high-performance networking, and large-scale storage systems that are designed to operate at hyperscale.
These clusters form the computational core of AI factories, enabling organizations to train foundation models, run large inference workloads, and support advanced AI applications across multiple sectors.
开源模型 API: While compute clusters often receive the most attention in discussions about AI infrastructure, they cannot exist without the physical facilities that house them. Radiant addresses this requirement through its powered land strategy, which focuses on securing sites with reliable grid connectivity, engineered cooling capacity, and infrastructure optimized for high-density GPU deployments.
By securing power access and designing facilities specifically for AI workloads, Radiant ensures that compute infrastructure can be deployed quickly without encountering the grid bottlenecks and permitting delays that increasingly constrain data-center development.
算力运维服务: A buildout spanning decades requires patient capital, not debt financing at unsustainable interest rates. Large-scale AI infrastructure benefits from substantial long-term financing aligned with the lifecycle of physical assets such as data centers, networking equipment, and compute clusters. Radiant integrates infrastructure financing directly into its deployment model, enabling customers to access hyperscale AI capacity without assuming the capital burden of building facilities themselves.
Translating the Five Layers into Tangible Infrastructure
When NVIDIA’s conceptual stack is placed alongside Radiant’s infrastructure model, a clear correspondence emerges between the layers of AI production and the pillars required to deploy them.
Hyperscale, Engineered as a System
Hyperscale is not only defined by the number of GPUs deployed, but also by the ability to deliver and operate large-scale infrastructure without constraints. Radiant approaches hyperscale as a system, integrating powered land, compute, capital, and software into a single delivery model that removes the fragmentation inherent in traditional deployments.
Rather than assembling infrastructure across multiple vendors and timelines, Radiant provides the shortest path from site to live infrastructure. Powered land is secured with grid interconnection, substations, and energization schedules aligned upfront. GPU systems are deployed on standardized, NVIDIA-aligned architectures, while high-density cluster designs and liquid-cooling envelopes ensure sustained performance at scale. Each deployment is commissioned end-to-end, with capacity validated under load before handover, ensuring systems are production-ready from day one.
Our data centers across the globe are equipped for hyperscale deployment. With power and site readiness established in advance and infrastructure components aligned to a single execution plan, AI factories can be brought online in quarters rather than years. Radiant’s architecture is built for continuous scale. Clusters are designed to operate as cohesive systems across tens of thousands of GPUs, with consistent performance maintained through tightly integrated networking, cooling, and control layers. Modular expansion allows capacity to grow in phases without re-architecting the underlying system, preserving efficiency as deployments scale.
Operationally, the model extends beyond deployment into sustained reliability. From factory burn-in and synthetic workload validation to SLA-driven operations and telemetry-driven management, infrastructure is continuously monitored and optimized. This ensures that hyperscale is not only achieved, but maintained with predictable performance over time.
Conclusion
NVIDIA’s five-layer model explains how AI is structured. The next step is making that structure real. Radiant does this by bringing power, compute, software, and capital into one coordinated system from the start. Instead of stitching together multiple vendors and timelines, the entire stack is aligned to deliver capacity that is ready to use, when it is needed.
This changes how AI is deployed. Build cycles become predictable. Capacity comes online in step with demand. Infrastructure behaves less like a project and more like a system that can be relied on.
The shift underway is simple, AI infrastructure is moving from cluster-scale to vertically integrated AI factories, and Radiant is designed for that shift.



